XLNet
XLNet Generalized Autoregressive Pretraining for Language Understanding
Abstract
Bert基于去噪自编码器的预训练模型,性能优于自回归语言模型的预训练方法。而由于mask一部分输入,bert忽略了被mask位置之间的依赖关系。
XLNet基于此优缺点可以
- 通过最大化所有可能的因式分解顺序的对数似然,学习双向语境信息
- 用自回归本身的特点克服bert的缺点
- 融合了自回归模型Transformer-XT的思路
作者从自回归(autoregressive)和自编码(autoencoding)两大范式分析了当前的预训练语言模型。
1 介绍
1.1 AutoRegression与AutoEncoding两大阵营
XLNet是一个类似BERT的模型,XLNet是一种通用的自回归预训练方法。
自回归(AutoRegression)语言模型
AR语言模型是一种使用上下文词来预测下一个词的模型,但是上下文单词被限制在两个方向,前向和后向。(例如:GPT,GPT-2)
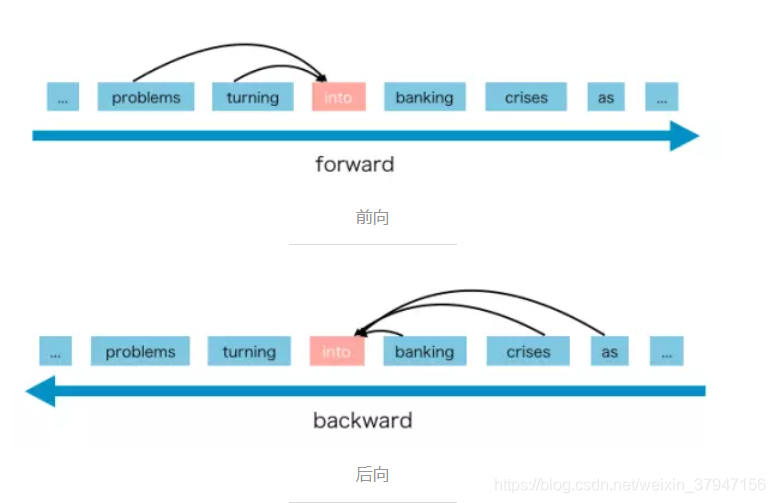
AR语言模型擅长生成式NLP任务,生成上下文时总是前向的。
但是AR只能使用前向上下文或后向上下文,这意味着它不能同时使用前向和后向上下文。
自编码(AutoEncoding)语言模型
BERT被归类为自编码器语言模型。AE旨在从损坏的输入中重建原始数据。
损坏的输入意味着我们在预训练阶段用[MASK]替换原始词,目标是预测得到原始句子。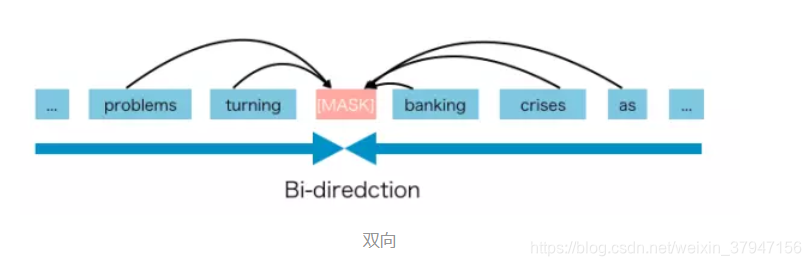
AE语言模型的优势是,它可以从前向和后向的方向看到上下文。
AE语言模型的缺点是
- [MASK]这种人为的符号在调优时在真实数据中并不存在,会导致预训练-调优的差异(pretrain-finetune discrepancy)
- [MASK]假设mask词在给定未mask词的情况下彼此独立(例:住房危机已经变成银行业危机。 其忽略了 银行业 与 危机 间的关系)。
1.2 两大阵营需要新的XLNet
XLNet提出了一种让AR语言模型从双向上下文中学习的新方法,以避免[MASK]方法在AE语言模型中带来的缺点。
XLNet是一种泛化自回归(AR)方法,既集合了AR和AE方法的优势,又避免了二者的缺陷。
- XLNet不使用传统AR模型中固定的前向或后向因式分解顺序,而是最大化所有可能因式分解顺序的期望对数似然,由于对因式分解顺序的排列操作,每个位置的语境都包含来自左侧和右侧的token。因此,每个位置都能学习来自所有位置的语境信息,即捕获双向语境。
- 作为一个泛化自回归(AR)模型,XLNet不依赖残缺数据。不会有BERT的预训练-微调差异。自回归目标提供一种自然的方式,来利用乘法法则对预测token的联合概率执行因式分解(factorize),这消除了BERT中的独立性假设。
- XLNet将Transformer-XL的分割循环机制和相对编码范式整合到预训练中。
2 Proposed Solution
2.1 在自回归模型中引入双向语言模型基本思想
XLNet仍然遵循两阶段的过程(pretrain fine-tune)。其主要希望改动第一阶段的过程,即不像BERT那样带[MASK]的Denoising-autoencoder的模式,而是采用AR语言模型的模式。
简单来说就是,输入句子X仍然使自左向右的输入,看到Ti单词的上文Context-before来预测Ti这个单词,又希望Context-before例不仅看到上文单词又能看到后面的Context-after里的下文单词。这样一来BERT预训练阶段引入的[MASK]符号就不需要了。
基本思想:在预训练阶段引入Permutation LM的训练目标。
举例:比如包含单词Ti的当前输入的句子X,由顺序的几个单词构成x1, x2, x3, x4四个单词顺序组成。假设x3为要预测的单词Ti,其所在的位置为Position 3,要想让它能够在上文Context-before中,也就是Pos 1或Pos 2的位置看到Pos 4的单词x4。可以这么做,假设固定住x3的位置,也就是仍在x3,之后随机排列组合句子中的4个单词,在所有可能里训责一部分作为模型的预训练的输入X。比如随机排列组合后x4, x2, x3, x1这样一个排列组合作为模型的输入X。于是x3就能同时看到上文x2以及下文x4的内容了。
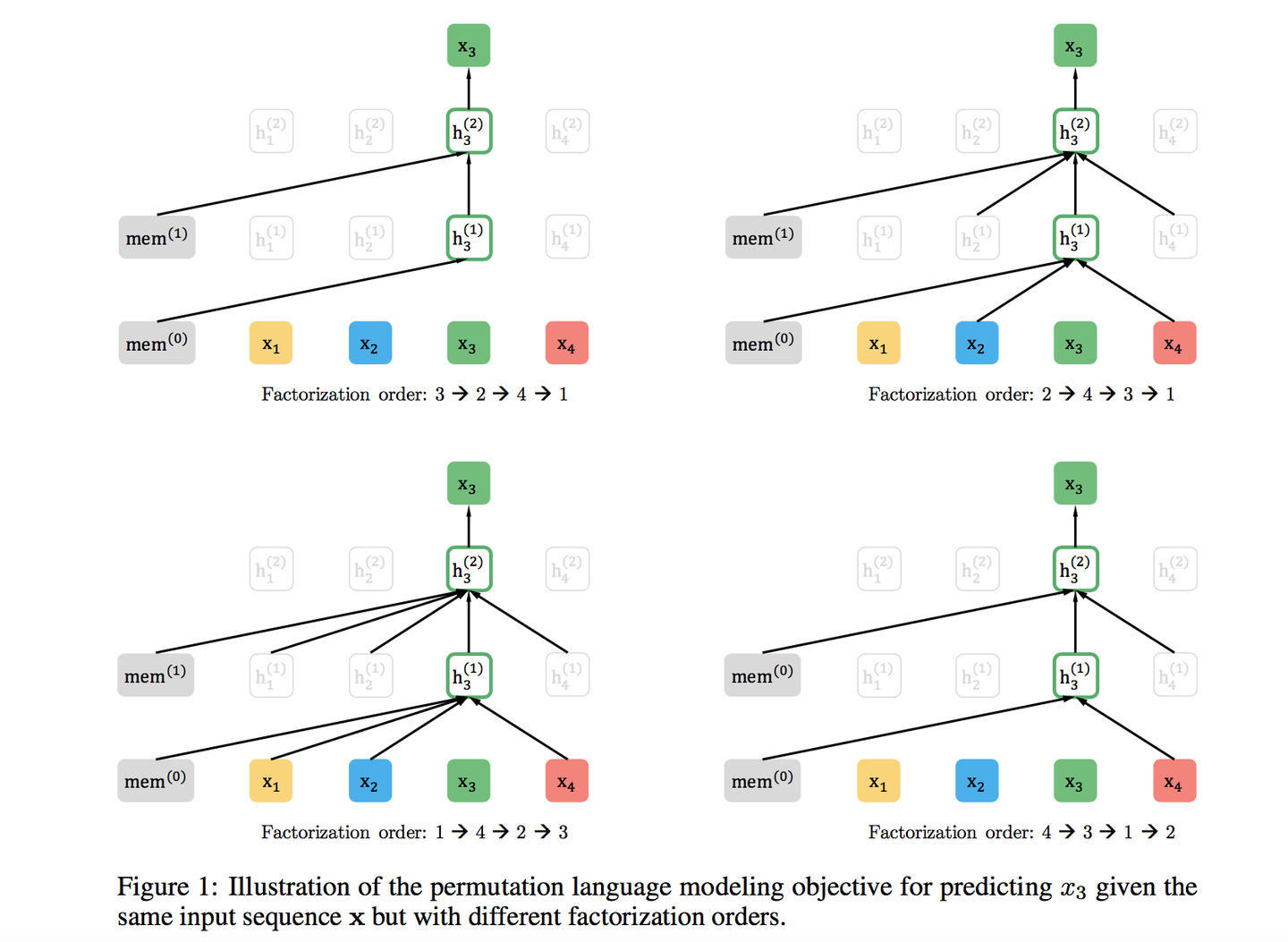
看上去仍然是个自回归的从左到右的模型,但是其实通过对句子中单词排列组合,把一部分Ti下文的单词排到Ti上文位置中,于是就看到了上文和下文,但是形式上看上去仍然是从左到右在预测后一个单词。
2.2 具体实现
尽管基本思想里提到把句子X的单词排列组合后,再随机抽取例子作为输入,但实际上不可以,因为Fine-tune阶段不可能去排列组合原始输入。所以必须让预训练阶段的输入部分看上去仍然是x1, x2, x3, x4这个顺序,但是可以在Transformer部分做些工作,来达成目标。
XLNet采取了Attention掩码机制,输入的X没有任何变化,单词Ti还是第i个单词,前面有1到i-1个单词。但是Transformer内部,通过Attention掩码从X的输入单词里,也就是Ti的Context-before和Context-after中随机选择i-1个单词,放到Ti的Context-before上,把其他单词的输入通过Attention掩码隐藏掉。(当然这个所谓放到Ti的上文位置,只是一种形象的说法,其实在内部,就是通过Attention Mask,把其它没有被选到的单词Mask掉,不让它们在预测单词Ti的时候发生作用,如此而已。看着就类似于把这些被选中的单词放到了上文Context_before的位置了)。
XLNet是用双流自注意力模型实现的。一个是内容流自注意力,其实就是标准的Transformer的计算过程,主要引入了Query流自注意力。其实就是用来替代[MASK]标记的,XLNet因为要抛弃[MASK]又不能看到x3的输入,于是Query流就直接忽略掉x3的输入,只保留这个位置信息,用参数w来代表位置的embedding编码。其实XLNet只是抛弃了[MASK]这个占位符号,内部还是引入Query流来忽略掉被MASK的这个单词。和BERT比只是实现方式不同而已。
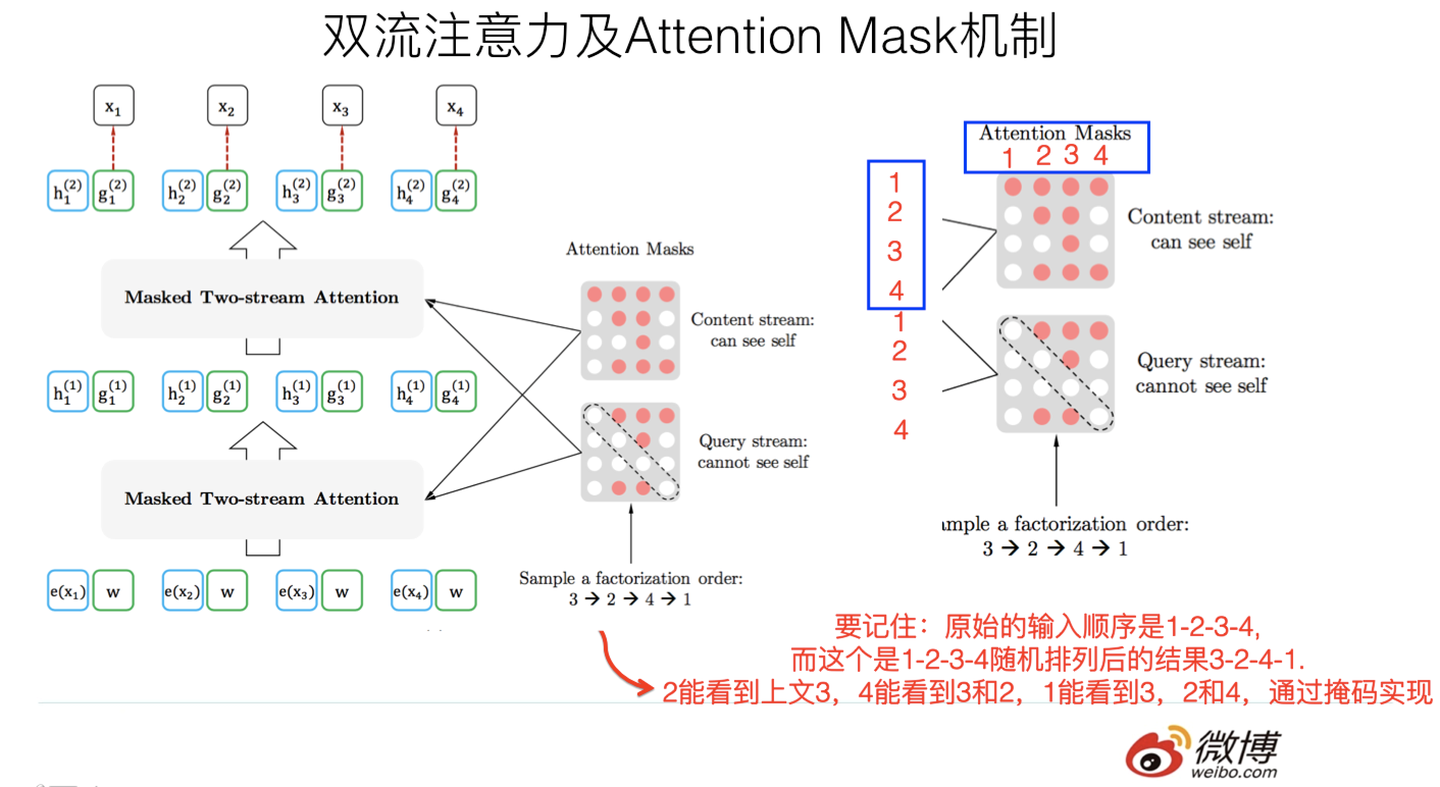
如图所示,输入序列仍是x1, x2, x3, x4,通过不同的掩码矩阵,让当前单词Xi只能看到被排列组合后的顺序x3->x2->x4->x1中自己前面的单词。
2.3 XLNet与BERT
通过改造BERT预训练的过程,其实可以模拟XLNet的PLM过程。
第一种思路:Bert目前的做法是,给定输入句子X,随机Mask掉15%的单词,然后要求利用剩下的85%的单词去预测任意一个被Mask掉的单词。对于输入句子,随机选择X中的任意i个单词,只用这i个单词去预测被Mask的单词。这个过程理论上可以在Transformer内采用Attention Mask来实现,这样BERT的预训练模型就和XLNet基本等价了。
第二种思路:假设仍使用BERT目前的Mask机制,将Mask 15%改为,每次一个句子只Mask掉一个单词,利用剩下的单词来预测被Mask掉的单词。因为XLNet在实现的时候,为了提升效率,其实是选择每个句子最后末尾的1/K个单词被预测,假设K=7,意味着一个句子X,只有末尾的1/7的单词会被预测。这样两者基本是等价的。
XLNet维持了自回归(AR)语言模型的从左向右的模式,这个BERT做不到。明显的好处是,对于生成类的任务,能够在维持表面从左向右的生成过程前提下,模型里隐含了上下文的信息。XLNet貌似应该对于生成类型的NLP任务,会比BERT又明显优势。此外,XLNet还引入了Transformer XL机制,所以对于长文档输入类型的NLP任务,也会比BERT有明显优势。
3 总结
Permutation Language Model是XLNet的主要理论创新,它开启了自回归(AR)语言模型如何引入下文的一个思路。
XLNet也相当于是BERT, GPT2.0, Transformer XL的综合体。
- 通过Permutation LM 预训练目标,吸收了BERT的双向语言模型;
- 吸收了GPT2.0使用更多更高质量的预训练数据;
- 吸收了Transformer XL的主要思想。
XLNet其实本质上还是ELMO/GPT/BERT这一系列两阶段模型的进一步延伸。在自回归(AR)语言模型方向引入双向语言模型打开了新思路。
未来预期
- Transformer天然对长文档任务处理有弱点,所以XLNet对于长文档NLP任务相比BERT应该有直接且比较明显的性能提升;
- 对于生成类的NLP任务,XLNet的预训练模式符合下游任务序列生成结果。
Rreference
https://zhuanlan.zhihu.com/p/70257427
https://blog.csdn.net/weixin_37947156/article/details/93035607
// AR AE LM 实现步骤?
// TODO Transformer 较于 RNN?
// TODO encoding decoding?
// TODO denoising-autoencoder?
// TODO Transformer-XL 分割循环机制 相对编码范式??
// TODO BERT 预训练-微调两阶段模式(pretrain fine-tune) 抛弃mask使两阶段保持一致? fine-tune阶段?
// TODO AR模型前向后向因式分解顺序?


