Paper | Attention
Intro
现在很多方法都在试图改进循环模型与Encoder-Decoder模型. 循环模型有一个致命的缺点就是无法并行, 在长序列中劣势更为明显.
Attention使得模型不用在意输入与输出序列之间的距离, 在这种架构下我们可以获得一个全局的依赖.
Background
现在的模型都有这个问题, 就是距离越远就越难获得它的依赖. Self-attention, intra-attention是同一意思注意力机制, 根据一个序列不同位置来计算整个序列的表示.
Model Architecture
Encoder将符号序列映射为一个连续的序列表示, 然后Decoder用这个z再转换为符号序列表示.
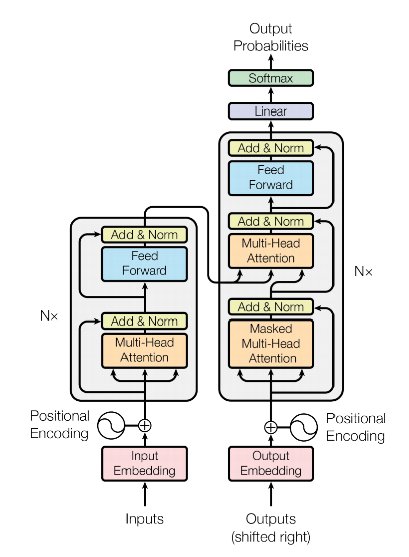
Encoder and Decoder Stacks
Encoder: 是由6个完全一样的层组成的, 每个层有两个子层, 第一层是multi-head self-attention, 第二层是全联接层. 在每个子层间有residual connection, 每个子层后有layer normalization.
$$
LayerNorm(x+Sublayer(x))
$$
Decoder: 是由6个完全一样的层组成的, 比Encoder多一个multi-head attention用来输入Encoder的输出. 并且修改了self-attention层可以让它从真实的output来获取信息, 而不是从input.
Attention
注意力可以背描述为一个query和一组key-values对到输出的映射. 他们全都是向量. 输出是由计算加权后的values的和得来的, 而权重是由query和对应key的一个方程计算而来的.
Scaled Dot-Product Attention
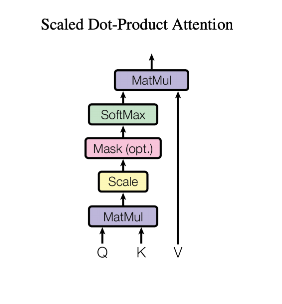
QK相乘, 计算softmax, 作为V的权重.
$$
Attention(Q, K, V) = softmax({QK^T\over\sqrt{d_k}})V
$$
这里经常用到两种attention function, 一种是additive attention, 一种是dot-product attention. Dot-product 就是上面的那个算法不带scaling的样子(1/sqrt{dk}).
对于较小的dk(Q, K的维度), 两种机制相近. 当大维度时, additive attention要胜过dot-product attention. 因此提出了通过一个scale来解决这个问题.
Multi-Head Attention
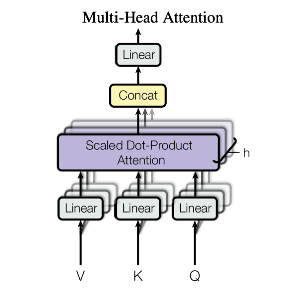
我们发现把QKV在不同的位置上分别映射h次, 得到dq, dk, dv维. 每次映射通过Scaled Dot-Product Attention输出一个values, 我们把这h次的values拼接, 再映射. 就得到了最终的values.
Multi-head attention 可以使模型从不同位置上的不同子空间获得信息表示.

我们使用了h=8的平行attention layers.
Application of Attention in our Model
Transformer使用multi-head attention 以3种不同的方式
- encoder-decoder attention 中query来自之前的decoder, 而key和value来自encoder的输出. 这使得所有的输入序列都参与到了decoder的每一个位置上.
- encoder包含self-attention. 在self-attention中, 所有的query, key, value都来自于同一个地方. 每个位置都可以参与到前一层的所有位置.
- 在decoder中包含self-attention. 同encoder一样. 我们还需要阻止左侧的信息流入decoder, 通过mask掉所有illegal的链接.
Position-wise Feed-Forward Networks
每一层还有一个Fully connected feed-forward network. 每个位置都独立且一致.
两次linear transformation和一个ReLU激活函数
$$
FFN(x) = max(0, xW_1+b_1)W_2+b_2
$$
Embeddings and Softmax
我们使用学到的embeddings去把input output tokens转换到d维的向量. 使用学到的线性变化和softmax去把decoder的输出转化到预测下一个token的概率.
Positional Encoding
我们需要引入一些信息去表示每个token在序列中相对或绝对位置.

每个位置的维度对应了一个正弦曲线, 使用正弦函数是因为可以表示相对距离.
Question
Neural sequence tranduction(转导)
decoder中的应用, mask?
Reference
| Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems. 2017. | |
| APA |